Translation Units
The translation units (tuples) used in the bilingual n-gram approach to SMT (BNSMT) are extracted from word alignments, in such a way that a unique segmentation of each bitext sentence pair is performed. Among the multiple unique segmentations that can be performed following word alignments, the one with the largest number of units (smallest units) is considered. The rationale behind producing small units is the aim for highly reusable (less sparse) units.
As typically taught on the well known phrase-based approach to SMT (PBSMT), a main drawback of using small units is the lack of translation context. However, in our model, context is introduced by means of using tuple n-grams, i.e. the model does not estimate probabilities over uncontextualized tuples but over sequences of tuples (n-grams).
Translation units (tuples)
Hence, the way unique segmentations are performed for each word-aligned training sentence pair becomes a critical point in our system. Our extraction algorithm follows three basic constraints:
- no word in a tuple is aligned to a word outside the tuple.
- the tuple segmentation preserves the monotonic word order of the target words (reorderings are allowed in the source words).
- no smallest tuples can be found without violating the previous constraints.
As outlined, source words may be reordered aiming at monotonizing the alignment, what produces the segmentation with the greatest number of tuples (smallest units). Let's see a few examples with several alignment configurations:
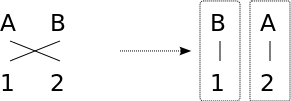
|
Source words are swapped to monotonize the alignment, hence producing the smallest possible tuples.
|
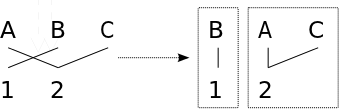
|
Source words A and B are reordered next to each other since both are linked to the same target word.
|
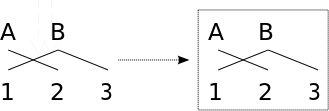
|
No permutation of source words exists which increases the number of tuples. Note that in order to monotonize the alignmet, target words should be reordered (what violates the second constraint).
|
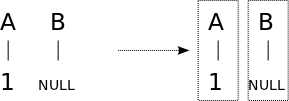
|
Target-NULLed tuples are allowed in our model. In decoding, the target NULL word is not considered as part of the translation hyptothesis.
|
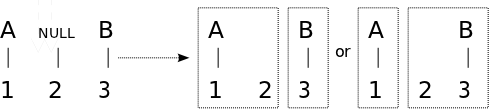
|
In contrast to the previous example, source-NULLed units are not allowed in our model. Hence, the target word aligned to NULL is attached to either the previous or the next tuple.
|
We typically call unfold, the procedure of reordering source words to monotonize the alignment, since it basically addresses the alignment monotonization by unfolding crossed links (shown in the previous first three examples). If you ran the French-English sample experiment, the file $here/fr2en/unfoldNULL contains the table of unfolded tuples extracted from the training bitext. An example of unfold sentence:
les ||| NULL ||| DET#UART ||| 0
opérations ||| operations ||| NOM ||| 1
NULL ||| there ||| NULL ||| -1
contre ||| against ||| PRP ||| 2
les ||| NULL ||| DET#UART ||| 3
des Talibans ||| Taliban ||| PRP#Udet NOM ||| 5 6
et ||| and ||| KON ||| 7
d' Al-Qaeda ||| al-Qaeda ||| PRP NOM ||| 8 9
forces ||| forces ||| NOM ||| 4
ont obtenu ||| brought ||| VER#Upres VER#Upper ||| 10 11
des ||| NULL ||| PRP#Udet ||| 12
mitigés ||| mixed ||| ADJ ||| 14
résultats ||| results ||| NOM ||| 13
. ||| . ||| SENT ||| 15
As it can be seen, the original French sentence:
les opérations contre les forces des Talibans et d' Al-Qaeda ont obtenu des résultats mitigés
has been reordered into:
les opérations contre les des Talibans et d' Al-Qaeda forces ont obtenu des mitigés résultats, hence, following an English word order.
Note that in addition to tuples (first and second fields), each line incorporates information about the Part-of-speech tags (third field) and original positions (last field) of the source words. Information which is used in further steps to collect rewrite rules.
Source-NULLed units
The process to decide wether an unaligned target word is attached to either the previous or the next tuple (see 'NULL ||| there' in the previous example) is performed by computing a probability for both configurations (previous and next). The configuration with highest probability is kept. In the case of our example, the two configurations are:
- previous: (opérations ||| operations there) + (contre ||| against)
- next: (opérations ||| operations) + (contre ||| there against)
The likelihood of each configuration is computed as: φ(tuple1) x φ(tuple2), where the tuple translation distributions φ(tuplei) are based on lexical weighting.
Following with the previous example, the file $here/fr2en/unfold contains the set of tuples without source-NULLed units:
les ||| NULL
opérations ||| operations
contre ||| there against
les ||| NULL
des Talibans ||| Taliban
et ||| and
d' Al-Qaeda ||| al-Qaeda
forces ||| forces
ont obtenu ||| brought
des ||| NULL
mitigés ||| mixed
résultats ||| results
. ||| .
Note that when k consecutive source-NULLed units are found, k+1 different configurations are considered. For instance, given the sequence of units:
x ||| a
NULL ||| b
NULL ||| c
y ||| d
Three configurations are taken into account:
- (x ||| a) + (y ||| b c d)
- (x ||| a b) + (y ||| c d)
- (x ||| a b c) + (y ||| d)
Factors
As we detail in section Feature functions, probability distributions over tuples are estimated following the n-gram language modeling approach. It is well known that long n-grams may suffer from sparseness problems, specially if we consider that our units are bilingual (with one or several source and target words).
In order to alleviate this problem, our system can estimate n-gram LM probabilities over tuples built from different factors: words (the base token), POS tags, lemmas, stems, etc. or any combination of the previous forms. You only need to indicate for each word-based tuple which is the corresponding factored version. For instance, the tuple 'ont obtenu ||| brought' would be associated with the POS tag factored form 'VER#Upres VER#Upper ||| VB'.
Equivalently to tuple n-gram language models, source and/or target n-gram language models can also be employed which refer to the factored forms of the tuple source or target side. For instance, we may use a source n-gram language model estimated over the training source words (or POS tags) after being reordered. Hence, performing as a reordering model, which scores reorderings performed in decoding according to those seen in training.
When translating unseen sentences, the decoder considers the use of the factored forms (see section Feature functions) when employing the corresponding language models (see section Decoding).